
U.S. Congress (Credit: Wikipedia)
“The 2020 polls featured polling error of an unusual magnitude,” according to a just released report by the American Association for Public Opinion Research (AAPOR). “It was the highest in 40 years for the national popular vote and the highest in at least 20 years for state-level estimates of the vote in presidential, senatorial, and gubernatorial contests.”
The AAPOR researchers, however, reported they could find no clear explanation for why the polls were so far off from the actual election results: 4.5 points off the results in national polls, 5.1 points for the state-level polls. While the report was able to rule out several possible explanations, the exact causes of the polling errors remain a mystery.
The researchers limited their investigation to national and statewide polls for president, governors, and senators. They did not investigate poll performance in the 435 congressional districts (CDs). I wanted to examine this.
To obtain the data necessary for such an investigation, I went to FiveThirtyEight, the Nate Silver website that uses polls among other factors to project election winners. Silver has made available all the data he used to predict the winning margin in each of the 435 CDs. As far as I know, there is no other website that makes such quantitative predictions and also makes available its data for others to analyze. (See Appendix at the end of this article for a description of the details of this analysis.)
FiveThirtyEight’s 2020 Performance
FiveThirtyEight’s overall projection gave Democrats a 97% chance of maintaining majority control of the House, which turned out to be correct.
The projection also gave the Democrats about a 70% chance of expanding their majority. In fact, Democrats lost 11 seats.
As shown in the table below, Silver’s 538 classified each CD race into one of seven categories: Solid Republican, Likely Republican, Lean Republican, Toss-up, Lean Democrat, Likely Democrat, Solid Democrat.
By itself, that classification is a rough projection. We would expect the toss-up CDs, for example, to split about evenly between the two parties, while all the solid Democratic CDs should produce Democratic winners and all the solid GOP CDs should produce Republican winners. In the “lean” and “likely” categories, we would expect the dominant party to prevail, though not win all the seats.
That’s not exactly how it played out in the election.
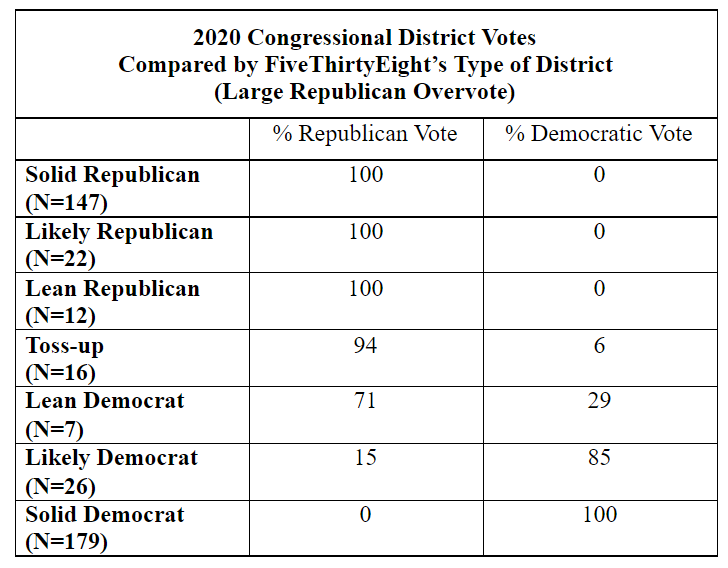
Only in the two solid categories, and in the likely Democrat category, did the expected results actually happen. Republicans won all the CDs in the Solid Republican category, and Democrats won all the seats in the Solid Democratic CDs.
In all other categories, there is a clear imbalance, with Republicans doing much better than Democrats.
The most startling overvote imbalances are in the Toss-up and Lean Democrat categories.
In the Toss-up category, for example, where we would expect about an even number of seats to be won by each party, Republicans won 15 of the sixteen seats, for a 94% win record. The probability of that outcome, if each contest was actually a toss-up, would be less than three hundredths of one percent.
In the Lean Democratic seats, Republicans won more seats (five of seven for 71%) than Democrats, when the opposite was predicted.
By contrast, Democrats won none of the 12 Lean Republican seats, though we would expect at least a few wins. The average chance of each Republican winning, as posted on FiveThirtyEight’s overall projection chart, was 65%. The likelihood that all 12 candidates would win is just six tenths of one percentage point.
These imbalances make clear how far off the mark were the FiveThirtyEight projections.
Unusual Percentage Discrepancies in FiveThirtyEight Projections
Overall, FiveThirtyEight underestimated GOP strength of support in the congressional districts by an average of 3.7 percentage points. But the projection error varied substantially by the type of CD.
As shown in the graph below, the largest under-estimation of GOP strength occurred in Solid Democrat CDs – an average of 5.9 percentage points. The size of the error declines as the CDs become more favorable to Republicans. In the Solid Republican CDs, the model underestimates Republican strength by less than half a percentage point (0.4%).
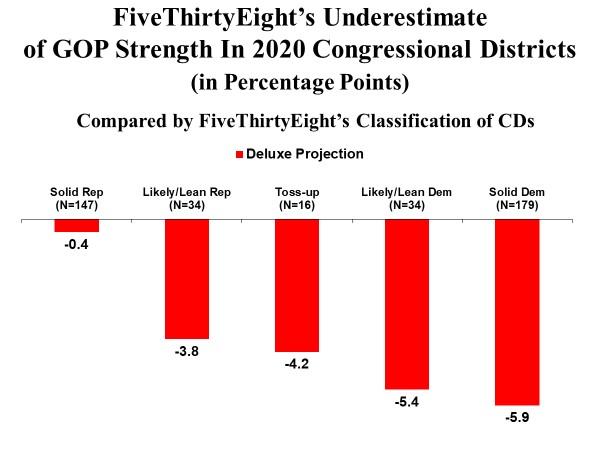
My first inclination was to attribute this pattern to the Distrustful GOP Voter hypothesis. The AAPOR report dismisses the idea that there were “shy” Trump voters, people who participated in a poll but then were reluctant to admit they supported Trump. As the report noted:
“It is plausible that Trump supporters were less likely to participate in polls overall. Nonetheless, among those who chose to respond to polls there is no evidence that respondents were lying.”
While the shy Trump voter explanation is ruled out, there is the plausibility of the “distrustful Trump voter,” a strong supporter who simply refuses to participate in the polls. The polls did not suffer from too few Republicans, so the hypothetical scenario outlined by the report is as follows:
“If the voters most supportive of Trump were least likely to participate in polls then the polling error may be explained as follows: Self-identified Republicans who choose to respond to polls are more likely to support Democrats and those who choose not to respond to polls are more likely to support Republicans. Even if the correct percentage of self-identified Republicans were polled, differences in the Republicans who did and did not respond could produce the observed polling error.”
The report argued that this scenario is not unreasonable, because Trump often excoriated the polls (and news media) as “fake,” perhaps leading his strongest supporters to refuse to participate in polls. That would mean that the self-identified Republicans who did participate in polls would, on average, reflect less support for Trump than the actual electorate (which, of course, would include those strong supporters).
While AAPOR researchers did not firmly embrace this hypothesis, the pattern in the above graph dealing with the congressional districts is consistent with that possibility. The pattern suggests that in districts where Republicans are surrounded by Democrats, strong Trump supporters are less likely to speak out or participate in polls than strong supporters in districts where they are the majority.
Thus, in the Solid Democrat CDs, FiveThirtyEight underestimated GOP strength, presumably because so many of the strong Trump supporters refused to participate in the polls. By contrast, in the Solid Republican CDs, strong Trump supporters feel comfortable in admitting their support and thus are willing to participate in the polls.
The Mystery Remains
The problem with this line of thinking is that FiveThirtyEight’s projections on the Solid Democrat and Solid Republicans CDs are probably not based very heavily on high-quality, publicly-released polls. Solid partisan districts remain solid for the same party for years, decades even, so there is little reason to conduct numerous high-quality polls in such districts. Instead, projections of winners are virtually automatic, with the projected percentages based, I would presume, largely on previous elections and demographic changes.
In the highly competitive CDs – the Toss-up and Lean categories – FiveThirtyEight’s underestimation of GOP support may reasonably be partially blamed on the faulty polls, noted by the AAPOR report.
But in the non-competitive CDs – at least in the Solid categories – polls may not be the major cause of FiveThirtyEight’s prediction errors. I’ve written to Nate Silver and will share any insights if there is a response.
The really mysterious pattern, initially brought to my attention by Jonathan Simon, is the large prediction error in the Solid Democrat category and the statistically insignificant error in the Solid Republican category.
What is there about the Solid Democratic category that apparently befuddles the FiveThirtyEight model, when the same model performs so well in the Solid Republican category?
Nate Silver — what do you think?
APPENDIX
While FiveThirtyEight presents the predictions of three models – Lite, Classic, and Deluxe – in this analysis, I’ve focused only on the deluxe model. That is the one on which the FiveThirtyEight chart titled, “Forecasting each House seat,” is based, suggesting that Silver believes it to be the default model for the public to view. It includes information based on poll results, additional relevant factors, and expert analysis.
I analyzed the FiveThirtyEight data provided on the website to come up with the means and the comparisons. My analysis is intended to focus on predictions involving Republicans and Democrats. The final number of CDs included in this analysis is 409. Fourteen CDs are excluded because the winners were uncontested (see below). Another 12 CDs are excluded because they did not pit a Republican against a Democrat (see below).
The following CDs are excluded because they were uncontested:
Solid Democratic CDs Uncontested:
- AL-7
- MA-1
- MA-3
- MA-7
- MA-8
- NC-12
- NY-5
- TN-5
Solid Republican CDs Uncontested:
- AL-5
- AL-6
- AR-1
- FL-2
- FL-25
- MS-4
The following CDs are excluded because they pit Democrats against Democrats.
- CA-12
- CA-18
- CA-29
- CA-34
- CA-38
- CA-44
- CA-53
- WA-10
The following CDs are excluded because they pit Democrats against non-Republicans
- IL-8
- NY-16
The following CDs are excluded because they pit Republicans against non-Democrats
- SD-1
- VA-9




